作者认为scala是最简单又方便的的语言, 懒人必备。
1.1什么是scala scala它是一门语言 学过的其他语言:java js shell c C++
1.2scala它是多范式的编程语言: (1)面向对象 (2)面向函数式编程 f(x)=y 函数式编程和它的高级特性(泛型,隐士类,隐士函数,隐士参数等等) 1.3 scala语言的优点: 快,代码简洁 1.4scala语言的缺点: 难以理解
2.1优雅: 这是框架设计师第一个要考虑的问题,框架的用户是应用开发的程序员,API是否优雅直接影响用户体验。 2.2速度快(开发速度快) Scala语言表达能力强,一行代码抵得上java多行,开发速度快。 2.3 Spark的开发语言(主要原因)
spark计算框架相当于mapreduce计算框架,基于内存,速度比mapreduce快100倍左右,后期的离线数据处理与实时数据处理。 因为spark框架的底层源码是由scala语言开发的, 学习Scala编程语言,为后续学习Spark和Kafka奠定基础。2.1 大家还记得hadoop中利用mapreduce程序运行worldcount程序吗? 2. (1)读数据,切分 3. (2)Word,1 4. (3)拿到一组相同key的数据,聚合 代码量多,繁琐
2.2看看我们的scala怎么处理的 在root目录下创建文件wc.txt 启动spark-shell程序
未排序:
sc.textFile(“/root/wc.txt”).flatMap(_.split(“ ”)).map((_,1)).reduceByKey(_+_).collect()默认排序:(升序)
sc.textFile(“/root/wc.txt”).flatMap(_.split(“ ”)).map((_,1)).reduceByKey(_+_).sortBy(_._2).collect()降序排序:
sc.textFile(“/root/wc.txt”).flatMap(_.split(“ ”)).map((_,1)).reduceByKey(_+_).sortBy(- _._2).collect()3.1安装JDK 因为scala是运行在JVM上的,所以要先安装JDK(1.8)
3.2windows安装scala: 这个我们就不细说了,大家解压,配置环境变量,之后再cmd命令中启动scala即可
3.3linux安装scala: (1)下载scala地址
https://downloads.lightbend.com/scala/2.11.8/scala-2.11.8.tgz (2)上传并解压Scala到制定目录 # tar -zxvf scala-2.11.8.tgz -C /usr/local/ (3)配置环境变量,将scala加入到PATH中 # vi /etc/profile export SCALA_HOME=/usr/local/scala-2.11.8 export PATH=$PATH:$JAVA_HOME/bin:$SCALA_HOME/bin (4)更新 Source /etc/profile 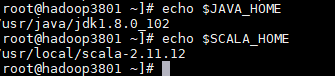因为图片加载不出来,手敲了一遍 root@hadoop3801 ~]# echo $JAVA_HOME usr/java/jsk1.8.0 102 root@hadoop3801 ~]# echo $SCALA_HOME usr/local/scala-2.11.12 root@hadoop3801 ~]# 注意:scala(2.11.12) 版本要与后面spark(2.21) 版本相匹配
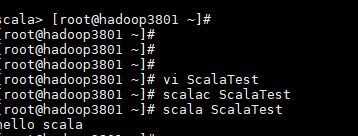
## linux下运行scala程序 - 4.1代码编写 #vi ScalaTest object ScalaTest{ def main(args:Array[String]):Unit={ print("hello scala") } } -4.2代码编译#scala ScalaTest
-4.3代码运行#scala ScalaTest
 我们发现这种方法编写代码效率太低,而且说不清楚,灵活性不好,等等,为了解决这个问题,我们来安装一个开发scala工具(idea) ## 6.Scala的基础语法(重点) **6.1数据类型** *scala中没有基本数据类型,全是包装数据类型 java 类比法 * 7种数值 : int long double float byte char short 2种非数值:Boolean(true false) java(void) scala(unit) **Unit 类型,没有返回值的类型(返回值为空)** - 引用数据类型:String - 任何类型: any (java object) **6.2变量(java中定义变量:数据类型 变量名=变量值)**String name=“小”
*两个关键字: val var Val: 不可变的 val name:String="小徐" Var: 可变的 var age:Int=20 * *scala中这样定义: 关键字 变量名:数据类型 =变量名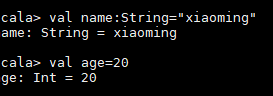 Val age:int=20 Val age=20 scala 会自动进行类型腿导,根据变量值,选择一个最合适的数据类型 神奇的下划线_:占位符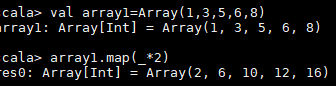 总结:两个关键字val var,语法:关键字,变量名:数据类型=变量值,数据类型可省略,编辑器能自动推导。 Val name="" **6.3表达式** if() XX if() xx else xx if () xx else if () xx else if () xx else 1. 条件表达式是有返回值的(区别于java) 2. 每一个分支的返回值,是由当前分支的最后一行的值来决定的 3. 如果某一个分支,只有一行语句,可以省略大括号,否则不省略 *6.4.1for* 增强for循环和普通的for循环 普通的for循环:需要借助生成器 to:左右都包括,[] until:包含左边,不包含右边[) 增强for循环和普通的for循环 符号: <- 普通的for循环中,两个生成器 to until 带守卫的for循环 for(i<- arr if i%2 ==0) 嵌套for循环 更好的方式,就是使用 函数式变成来实现 **6.4.2 while** 无限制循环(只要成立就执行) **6.4.3{}while()** 先执行一次,然后再执行判断 ## Scala方法和函数(重难点) 可以认为方法就是一种特殊函数。 java做什么事? 方法是一段业务的综合,代码的复用 方法和函数,可以实现同样的功能,写法上不一样。 public static String sum(){} ## 8.1方法 定义方法的关键字:def java(public ) 怎么定义:def sum(x:Int,y:Int):Int={x+y} def 方法的名称(参数列表):返回值类型 = { 方法体 } ## 8.2函数 => 定义函数的第一种方式:简写 => f(a)=>b val 函数名=(函数的参数列表)=> {函数体的内容} val fun1=(a:Int,b:Int)=>{if(a>b) a else b}  返回一个函数的签名: 包含:函数的名称,输入的类型 => 返回值类型 该函数有2个输入参数。 **第二种写法** 函数的名称(参数列表) Val fun1:(Int,Int)=>Int=(a,b)=>{a*b} 函数的第二种定义方式: val 函数名:(输入参数类型)=>(返回值类型) = (输入参数的引用)=> 函数体内容 函数可以作为独立的表达式存在,返回的内容就是函数的签名信息(方法必须调用,方法不能作为单独的表达式存在) ## 8.3方法和函数的区别: *函数,头等公民,地位更高* scala中,方法和函数有什么区别? 1. 定义方式,方法的关键字def,函数的关键形式 => 2. 函数可以作为单独的表达式来存在,返回的是签名信息,而方法不能。 3. 函数可以当作方法的参数,和返回值类型。 也就是说,定义一个方法,**参数可以是函数,返回值类型也可以是函数。** 方法可以转化为函数: **val 函数名 = 方法名称 _(记住有空格)** def sun() val fun3=sun_ **## 扩展** 1,闭包:就是函数的嵌套:既:在一个函数定义中,包含另外一个函数的定义:并且在内函数中可以访问外函数中的变量(见代码) ) 2,函数的求职策略: 函数有两种求职策略 (1) call by value:求职策略 对函数的实参求值:求职策略 (2) call by name:求名策略 函数的实参在函数体内部用到的时候每次都会被求值(见代码)